Abstract
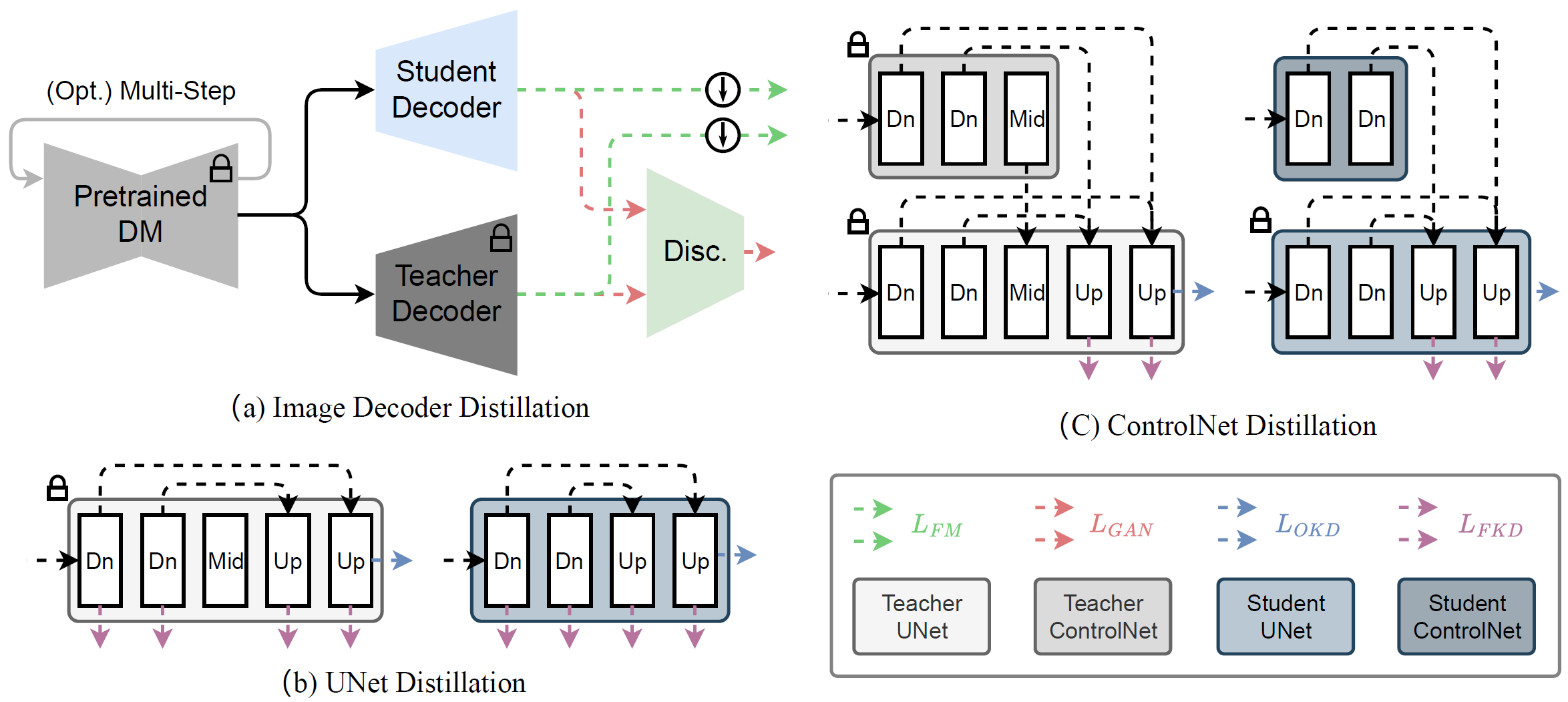
Recent advancements in diffusion models have positioned them at the forefront of image generation. Despite their superior performance, diffusion models are not without drawbacks; they are characterized by complex architectures and substantial computational demands, resulting in significant latency due to their iterative sampling process. To mitigate these limitations, we introduce a dual approach involving model miniaturization and a reduction in sampling steps, aimed at significantly decreasing model latency. Our methodology leverages knowledge distillation to streamline the U-Net and image decoder architectures, and introduces an innovative one-step DM training technique that utilizes feature matching and score distillation. We present two models, SDXS-512 and SDXS-1024, achieving inference speeds of approximately 100 FPS (30x faster than SD v1.5) and 30 FPS (60x faster than SDXL) on a single GPU, respectively. Moreover, our training approach offers promising applications in image-conditioned control, facilitating efficient image-to-image translation.
Overview
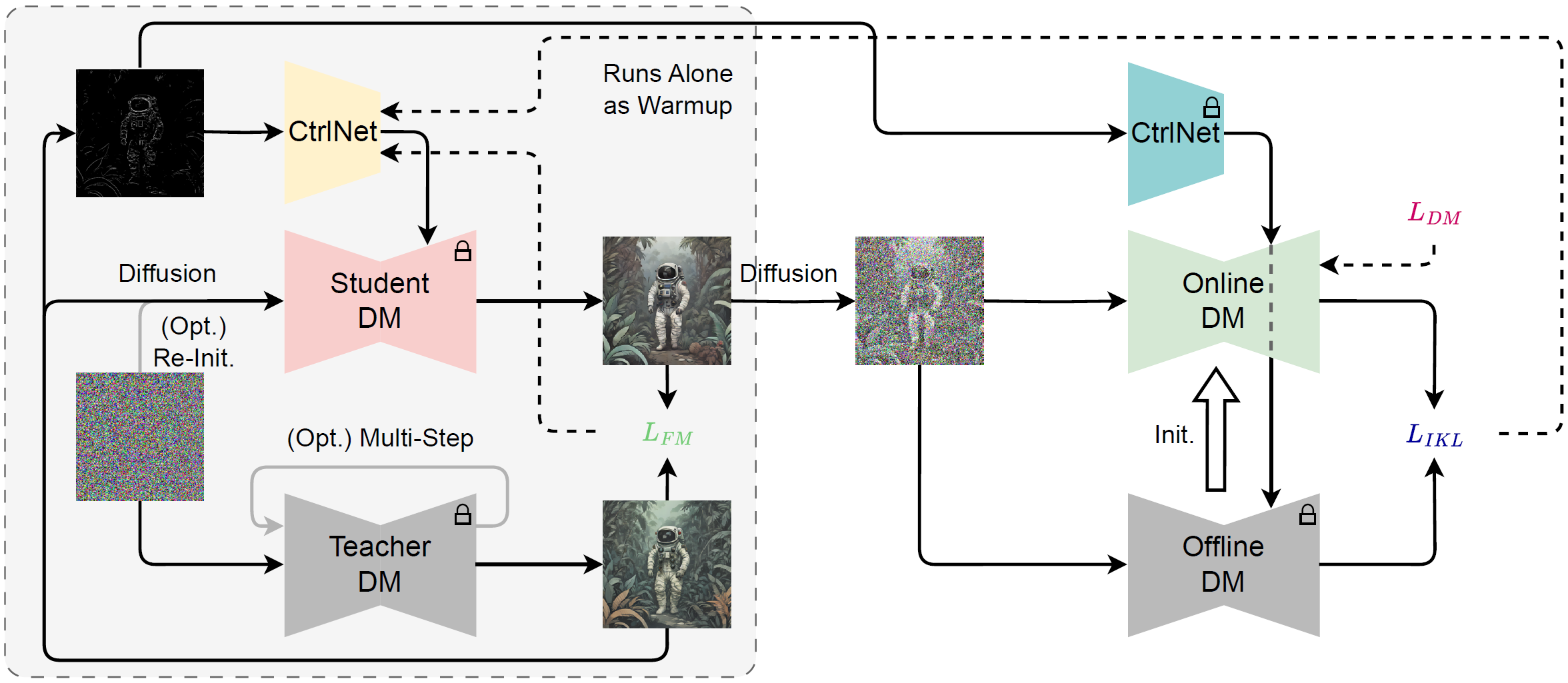
Assuming the image generation time is limited to 1 second, then SDXL can only use 16 NFEs to produce a slightly blurry image, while SDXS-1024 can generate 30 clear images. Besides, our proposed method can also train ControlNet.
Method
Model Acceleration

Text-to-Image
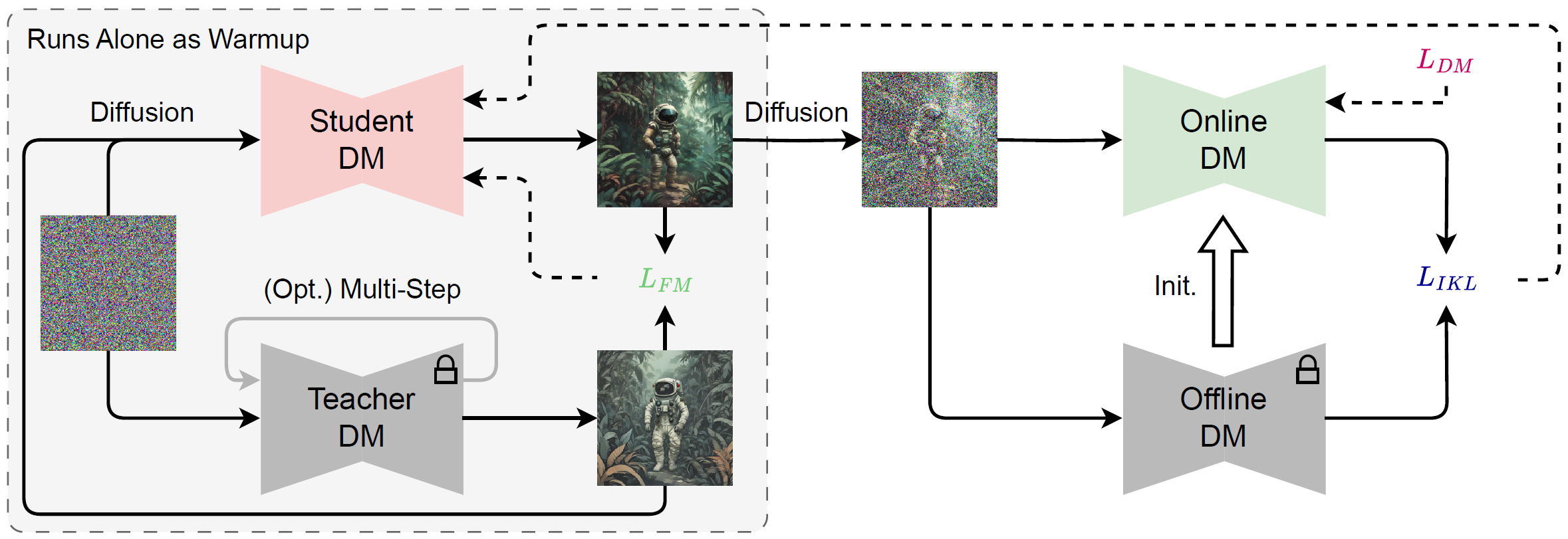

Image-to-Image